
Faculty at CISPA, Member of the European Lab for Learning and Intelligent Systems (ELLIS).
News & Open Positions
- [fully-funded postdoc position] Applications are invited for a postdoc position in my group. Find more details (and how to apply) here.
- Contact form: [Postdoc application]. I am reviewing applications on a rolling basis.
- [fully-funded PhD position, ERC CollectiveMinds] Applications are invited for a fully funded 4-year PhD position.
- Contact form: [PhD application]. I am reviewing applications on a rolling basis.
- I am also accepting ELLIS PHD candidates (application deadline: 15 November 2025). If you apply to ELLIS and want to work with me, drop me an email.
- Please note that I may not be able to respond to every email immediately, but I will do my best to reply as soon as possible. Thank you for your patience!
-
I am always looking for strong postdocs, PhD students, interns, HiWis, master theses, or other research collaborations possible (see here).
If you are interested in applying for a position, please read this page and send me an email detailing your research interests and motivation, and attach your CV (and possibly your transcript). - [Teaching Summer 25]: I am teaching an advanced course on Modern Optimization Methods together with Anton Rodomanov.
- [Teaching Summer 24]: I am teaching an advanced lecture on Optimization for Machine Learning at Saarland University.
- [Teaching Winter 23]: I am teaching an advanced lecture on Games in Machine Learning together with Tatjana Chavdarova [Tatjana's Course Slides].
- [June 2025] I am happy to announce that I was appointed as tenured faculty at CISPA.
- [December 2024] I am honored to be awarded an ERC Consolidator Grant 2024 for our project CollectiveMinds.
- Join me on this exciting journey! If you are interested in a PostDoc or PhD position specifically related to this project, please include [CollectiveMinds] in the subject line when reaching out via email.
- [December 2024] Co-organizing the optimization workshop at NeurIPS 2024
- [August 2024] First time at KDD, for a keynote at the FedKDD workshop.
- [June 2024] Plenary speaker at the EUROPT Conference on Advances in Continuous Optimization (EUROPT 2024) on A Universal Framework for Federated Optimization [Slides].
- [September 2023] I am honored to receive a Google Reserach Scholar Award.
- [August 2022] I am honored to receive a Meta Privacy-Enhancing Technologies Research Award.
- [June 24, 21] Invited keynote talk on Efficient Federated Learning Algorithms [Slides] at the FL-ICML 2021 Workshop.
Team (PhD students & Postdocs)
- Dr. Anton Rodomanov (since 09/2023)
- Dr. Rotem Mulayoff (since 09/2024)
- Xiaowen Jiang (since 01/2023)
- Yuan Gao (since 06/2023)
- Polina Dolgova (since 07/2025)
Alumni
- Anastasia Koloskova (defended 11/2024)
Research Interests
- optimization for machine learning
- methods for collaborative learning (distributed, federated and decentralized methods)
- efficient optimization methods
- adaptive stochastic methods and generalization performance
- theory of deep learning
- privacy and security in machine learning
Workshops (Organizer)
-
17th OPT Workshop on Optimization for Machine Learning at NeurIPS, co-organizer
December 6, 2025, San Diego, USA.
Reviewing for
- Conferences: International Conference on Learning Representations (ICLR)24 (area chair)2322International Conference on Machine Learning (ICML)24 (area chair)23 (area chair)2220191817Conference on Computer Vision and Pattern Recognition (CVPR)2224Genetic and Evolutionary Computation Conference (GECCO)2423222120191817161514International Conference on Artificial Intelligence and Statistics (AISTATS)2423222019Neural Information Processing Systems (NeurIPS)23 (area chair)22 (area chair)22 (area chair)21 (area chair)201918Parallel Problem Solving from Nature (PPSN)222018International Symposium on Computational Geometry (SoCG)21Symposium on Discrete Algorithms (SODA)19Symposium on the Theory of Computing (STOC)18
- Journals: Annals of Statistics (AOS)Artificial Intelligence (ARTINT)Computational Optimization and Application (COAP)European Journal of Operational Research (EJOR)IEEE Journal on Selected Areas in Information Theory (JSAIT)IEEE Transactions on Evolutionary Computation (TEVC)IEEE Transactions on Pattern Analysis and Machine Learning (TPAMI)IEEE Transactions on Signal Processing (TSP)Journal of Machine Learning Research (JMLR)Machine Learning (MACH)Markov Processes And Related Fields (MPRF)Mathematical Programming (MAPR)Numerical Algebra, Control and Optimization (NACO)Optimization Methods and Software (OMS)SIAM Journal on Mathematics of Data Science (SIMODS)SIAM Journal on Optimization (SIOPT)
- Workshops: NeurIPS Workshop on Optimization for Machine Learning (OPT)2322212019International Workshop on Trustable, Verifiable and Auditable Federated Learning in Conjunction with AAAI 2022 (FL-AAAI-22)22International Workshop on Federated Learning for User Privacy and Data Confidentiality (FL-ICML)2120
Editorial Board
Education and Work
- since Dec 1 2021, TT Faculty at CISPA.
- since June 2020, member of the European Lab for Learning and Intelligent Systems.
- From Dec 1 2016 to Nov 30 2021, research scientist at EPFL, hosted by Prof. Martin Jaggi, Machine Learning and Optimization Laboratory (MLO).
- From Nov 1 2014 to Oct 31 2016, I worked with Prof. Yurii Nesterov and Prof. François Glineur at the Center for Operations Research and Econometrics (CORE) and the ICTEAM.
- From Sep 15 2010 to Sep 30 2014, I was a PHD student in Prof. Emo Welzl's research group, supervised by Prof. Bernd Gärtner and Christian Lorenz Müller.
- From Sep 2005 to Mar 2010 I did my Bachelor and Master in Mathematics at ETH Zurich.
Publications
I became too busy to update this list regularly. Please check my Google Scholar Profile to see what I have been working on recently.Refereed Publications
- Simultaneous Training of Partially Masked Neural NetworksAbstractIn:AISTATS2022For deploying deep learning models to lower end devices, it is necessary to train less resource-demanding variants of state-of-the-art architectures. This does not eliminate the need for more expensive models as they have a higher performance. In order to avoid training two separate models, we show that it is possible to train neural networks in such a way that a predefined 'core' subnetwork can be split-off from the trained full network with remarkable good performance. We extend on prior methods that focused only on core networks of smaller width, while we focus on supporting arbitrary core network architectures. Our proposed training scheme switches consecutively between optimizing only the core part of the network and the full one. The accuracy of the full model remains comparable, while the core network achieves better performance than when it is trained in isolation. In particular, we show that training a Transformer with a low-rank core gives a low-rank model with superior performance than when training the low-rank model alone. We analyze our training scheme theoretically, and show its convergence under assumptions that are either standard or practically justified. Moreover, we show that the developed theoretical framework allows analyzing many other partial training schemes for neural networks.
- The Peril of Popular Deep Learning Uncertainty Estimation MethodsAbstractCodeIn:NeurIPS 2021 Workshop: Bayesian Deep Learning2021Uncertainty estimation (UE) techniques -- such as the Gaussian process (GP), Bayesian neural networks (BNN), Monte Carlo dropout (MCDropout) -- aim to improve the interpretability of machine learning models by assigning an estimated uncertainty value to each of their prediction outputs. However, since too high uncertainty estimates can have fatal consequences in practice, this paper analyzes the above techniques. Firstly, we show that GP methods always yield high uncertainty estimates on out of distribution (OOD) data. Secondly, we show on a 2D toy example that both BNNs and MCDropout do not give high uncertainty estimates on OOD samples. Finally, we show empirically that this pitfall of BNNs and MCDropout holds on real world datasets as well. Our insights (i) raise awareness for the more cautious use of currently popular UE methods in Deep Learning, (ii) encourage the development of UE methods that approximate GP-based methods -- instead of BNNs and MCDropout, and (iii) our empirical setups can be used for verifying the OOD performances of any other UE method.
- An Improved Analysis of Gradient Tracking for Decentralized Machine LearningAbstractPosterIn:NeurIPS342021We consider decentralized machine learning over a network where the training data is distributed across agents, each of which can compute stochastic model updates on their local data. The agent's common goal is to find a model that minimizes the average of all local loss functions. While gradient tracking (GT) algorithms can overcome a key challenge, namely accounting for differences between workers' local data distributions, the known convergence rates for GT algorithms are not optimal with respect to their dependence on the mixing parameter (related to the spectral gap of the connectivity matrix). We provide a tighter analysis of the GT method in the stochastic strongly convex, convex and non-convex settings. We improve the dependency on p from p to pc in the noiseless case and from p to pc in the general stochastic case, where c>p is related to the negative eigenvalues of the connectivity matrix (and is a constant in most practical applications). This improvement was possible due to a new proof technique which could be of independent interest.
- RelaySum for Decentralized Deep Learning on Heterogeneous DataAbstractCodeIn:NeurIPS342021In decentralized machine learning, workers compute model updates on their local data. Because the workers only communicate with few neighbors without central coordination, these updates propagate progressively over the network. This paradigm enables distributed training on networks without all-to-all connectivity, helping to protect data privacy as well as to reduce the communication cost of distributed training in data centers. A key challenge, primarily in decentralized deep learning, remains the handling of differences between the workers' local data distributions. To tackle this challenge, we introduce the RelaySum mechanism for information propagation in decentralized learning. RelaySum uses spanning trees to distribute information exactly uniformly across all workers with finite delays depending on the distance between nodes. In contrast, the typical gossip averaging mechanism only distributes data uniformly asymptotically while using the same communication volume per step as RelaySum. We prove that RelaySGD, based on this mechanism, is independent of data heterogeneity and scales to many workers, enabling highly accurate decentralized deep learning on heterogeneous data.
- Breaking the centralized barrier for cross-device federated learning (aka MIME)AbstractCodeIn:NeurIPS342021Federated learning (FL) is a challenging setting for optimization due to the heterogeneity of the data across different clients which gives rise to the client drift phenomenon. In fact, obtaining an algorithm for FL which is uniformly better than simple centralized training has been a major open problem thus far. In this work, we propose a general algorithmic framework, Mime, which i) mitigates client drift and ii) adapts arbitrary centralized optimization algorithms such as momentum and Adam to the cross-device federated learning setting. Mime uses a combination of control-variates and server-level statistics (e.g. momentum) at every client-update step to ensure that each local update mimics that of the centralized method run on iid data. We prove a reduction result showing that Mime can translate the convergence of a generic algorithm in the centralized setting into convergence in the federated setting. Further, we show that when combined with momentum based variance reduction, Mime is provably faster than any centralized method--the first such result. We also perform a thorough experimental exploration of Mime's performance on real world datasets.
- Semantic Perturbations with Normalizing Flows for Improved GeneralizationAbstractIn:ICCV (extended abstract in: ICML Workshop on Invertible Neural Networks, Normalizing Flows, and Explicit Likelihood Models)2021Data augmentation is a widely adopted technique for avoiding overfitting when training deep neural networks. However, this approach requires domain-specific knowledge and is often limited to a fixed set of hard-coded transformations. Recently, several works proposed to use generative models for generating semantically meaningful perturbations to train a classifier. However, because accurate encoding and decoding are critical, these methods, which use architectures that approximate the latent-variable inference, remained limited to pilot studies on small datasets. Exploiting the exactly reversible encoder-decoder structure of normalizing flows, we perform on-manifold perturbations in the latent space to define fully unsupervised data augmentations. We demonstrate that such perturbations match the performance of advanced data augmentation techniques -- reaching 96.6% test accuracy for CIFAR-10 using ResNet-18 and outperform existing methods, particularly in low data regimes -- yielding 10--25% relative improvement of test accuracy from classical training. We find that our latent adversarial perturbations adaptive to the classifier throughout its training are most effective, yielding the first test accuracy improvement results on real-world datasets -- CIFAR-10/100 -- via latent-space perturbations.
- Quasi-Global Momentum: Accelerating Decentralized Deep Learning on Heterogeneous DataAbstractVideoIn:ICML2021Decentralized training of deep learning models is a key element for enabling data privacy and on-device learning over networks. In realistic learning scenarios, the presence of heterogeneity across different clients' local datasets poses an optimization challenge and may severely deteriorate the generalization performance. In this paper, we investigate and identify the limitation of several decentralized optimization algorithms for different degrees of data heterogeneity. We propose a novel momentum-based method to mitigate this decentralized training difficulty. We show in extensive empirical experiments on various CV/NLP datasets (CIFAR-10, ImageNet, AG News, and SST2) and several network topologies (Ring and Social Network) that our method is much more robust to the heterogeneity of clients' data than other existing methods, by a significant improvement in test performance (1%−20%).
- Consensus Control for Decentralized Deep LearningAbstractVideoIn:ICML2021Decentralized training of deep learning models enables on-device learning over networks, as well as efficient scaling to large compute clusters. Experiments in earlier works reveal that, even in a data-center setup, decentralized training often suffers from the degradation in the quality of the model: the training and test performance of models trained in a decentralized fashion is in general worse than that of models trained in a centralized fashion, and this performance drop is impacted by parameters such as network size, communication topology and data partitioning. We identify the changing consensus distance between devices as a key parameter to explain the gap between centralized and decentralized training. We show in theory that when the training consensus distance is lower than a critical quantity, decentralized training converges as fast as the centralized counterpart. We empirically validate that the relation between generalization performance and consensus distance is consistent with this theoretical observation. Our empirical insights allow the principled design of better decentralized training schemes that mitigate the performance drop. To this end, we propose practical training guidelines for the data-center setup as the important first step.
- Critical Parameters for Scalable Distributed Learning with Large Batches and Asynchronous UpdatesAbstractVideoIn:AISTATS2021It has been experimentally observed that the efficiency of distributed training with stochastic gradient (SGD) depends decisively on the batch size and -- in asynchronous implementations -- on the gradient staleness. Especially, it has been observed that the speedup saturates beyond a certain batch size and/or when the delays grow too large. We identify a data-dependent parameter that explains the speedup saturation in both these settings. Our comprehensive theoretical analysis, for strongly convex, convex and non-convex settings, unifies and generalized prior work directions that often focused on only one of these two aspects. In particular, our approach allows us to derive improved speedup results under frequently considered sparsity assumptions. Our insights give rise to theoretically based guidelines on how the learning rates can be adjusted in practice. We show that our results are tight and illustrate key findings in numerical experiments.
- LENA: Communication-Efficient Distributed Learning with Self-Triggered Gradient UploadsAbstractVideoIn:AISTATS2021In distributed optimization, parameter updates from the gradient computing node devices have to be aggregated in every iteration on the orchestrating server. When these updates are sent over an arbitrary commodity network, bandwidth and latency can be limiting factors. We propose a communication framework where nodes may skip unnecessary uploads. Every node locally accumulates an error vector in memory and self-triggers the upload of the memory contents to the parameter server using a significance filter. The server then uses a history of the nodes’ gradients to update the parameter. We characterize the convergence rate of our algorithm in smooth settings (strongly-convex, convex, and non-convex) and show that it enjoys the same convergence rate as when sending gradients every iteration, with substantially fewer uploads. Numerical experiments on real data indicate a significant reduction of used network resources (total communicated bits and latency), especially in large networks, compared to state-of-the-art algorithms. Our results provide important practical insights for using machine learning over resource-constrained networks, including Internet-of-Things and geo-separated datasets across the globe.
- A Linearly Convergent Algorithm for Decentralized Optimization: Sending Less Bits for Free!AbstractVideoIn:AISTATS2021Decentralized optimization methods enable on-device training of machine learning models without a central coordinator. In many scenarios communication between devices is energy demanding and time consuming and forms the bottleneck of the entire system. We propose a new randomized first-order method which tackles the communication bottleneck by applying randomized compression operators to the communicated messages. By combining our scheme with a new variance reduction technique that progressively throughout the iterations reduces the adverse effect of the injected quantization noise, we obtain a scheme that converges linearly on strongly convex decentralized problems while using compressed communication only. We prove that our method can solve the problems without any increase in the number of communications compared to the baseline which does not perform any communication compression while still allowing for a significant compression factor which depends on the conditioning of the problem and the topology of the network. Our key theoretical findings are supported by numerical experiments.
- Taming GANs with Lookahead-MinmaxAbstractVideoIn:ICLR2021Generative Adversarial Networks are notoriously challenging to train. The underlying minmax optimization is highly susceptible to the variance of the stochastic gradient and the rotational component of the associated game vector field. To tackle these challenges, we propose the Lookahead algorithm for minmax optimization, originally developed for single objective minimization only. The backtracking step of our Lookahead–minmax naturally handles the rotational game dynamics, a property which was identified to be key for enabling gradient ascent descent methods to converge on challenging examples often analyzed in the literature. Moreover, it implicitly handles high variance without using large mini-batches, known to be essential for reaching state of the art performance. Experimental results on MNIST, SVHN, CIFAR-10, and ImageNet demonstrate a clear advantage of combining Lookahead–minmax with Adam or extragradient, in terms of performance and improved stability, for negligible memory and computational cost. Using 30-fold fewer parameters and 16-fold smaller minibatches we outperform the reported performance of the class-dependent BigGAN on CIFAR-10 by obtaining FID of 12.19 without using the class labels, bringing state-of-the-art GAN training within reach of common computational resources.
- Ensemble Distillation for Robust Model Fusion in Federated LearningAbstractVideoIn:NeurIPS332020Federated Learning (FL) is a machine learning setting where many devices collaboratively train a machine learning model while keeping the training data decentralized. In most of the current training schemes the central model is refined by averaging the parameters of the server model and the updated parameters from the client side. However, directly averaging model parameters is only possible if all models have the same structure and size, which could be a restrictive constraint in many scenarios.
In this work we investigate more powerful and more flexible aggregation schemes for FL. Specifically, we propose ensemble distillation for model fusion, i.e. training the central classifier through unlabeled data on the outputs of the models from the clients. This knowledge distillation technique mitigates privacy risk and cost to the same extent as the baseline FL algorithms, but allows flexible aggregation over heterogeneous client models that can differ e.g. in size, numerical precision or structure. We show in extensive empirical experiments on various CV/NLP datasets (CIFAR-10/100, ImageNet, AG News, SST2) and settings (heterogeneous models/data) that the server model can be trained much faster, requiring fewer communication rounds than any existing FL technique so far. - The Error-Feedback Framework: Better Rates for SGD with Delayed Gradients and Compressed CommunicationAbstractBibJournal of Machine Learning ResearchJMLR 21(237), 1–362020We analyze (stochastic) gradient descent (SGD) with delayed updates on smooth quasi-convex and non-convex functions and derive concise, non-asymptotic, convergence rates. We show that the rate of convergence in all cases consists of two terms: (i) a stochastic term which is not affected by the delay, and (ii) a higher order deterministic term which is only linearly slowed down by the delay. Thus, in the presence of noise, the effects of the delay become negligible after a few iterations and the algorithm converges at the same optimal rate as standard SGD. This result extends a line of research that showed similar results in the asymptotic regime or for strongly-convex quadratic functions only. We further show similar results for SGD with more intricate form of delayed gradients&emdash;compressed gradients under error compensation and for localSGD where multiple workers perform local steps before communicating with each other. In all of these settings, we improve upon the best known rates. These results show that SGD is robust to compressed and/or delayed stochastic gradient updates. This is in particular important for distributed parallel implementations, where asynchronous and communication efficient methods are the key to achieve linear speedups for optimization with multiple devices.
- A Unified Theory of Decentralized SGD with Changing Topology and Local UpdatesAbstractVideoIn:ICML2020Decentralized stochastic optimization methods have gained a lot of attention recently, mainly because of their cheap per iteration cost, data locality, and their communication-efficiency. In this paper we introduce a unified convergence analysis that covers a large variety of decentralized SGD methods which so far have required different intuitions, have different applications, and which have been developed separately in various communities. Our algorithmic framework covers local SGD updates and synchronous and pairwise gossip updates on adaptive network topology. We derive universal convergence rates for smooth (convex and non-convex) problems and the rates interpolate between the heterogeneous (non-identically distributed data) and iid-data settings, recovering linear convergence rates in many special cases, for instance for over-parametrized models. Our proofs rely on weak assumptions (typically improving over prior work in several aspects) and recover (and improve) the best known complexity results for a host of important scenarios, such as for instance coorperative SGD and federated averaging (local SGD).
- Extrapolation for Large-batch Training in Deep LearningAbstractVideoIn:ICML2020Deep learning networks are typically trained by Stochastic Gradient Descent (SGD) methods that iteratively improve the model parameters by estimating a gradient on a very small fraction of the training data. A major roadblock faced when increasing the batch size to a substantial fraction of the training data for improving training time is the persistent degradation in performance (generalization gap). To address this issue, recent work propose to add small perturbations to the model parameters when computing the stochastic gradients and report improved generalization performance due to smoothing effects. However, this approach is poorly understood; it requires often model-specific noise and fine-tuning. To alleviate these drawbacks, we propose to use instead computationally efficient extrapolation (extragradient) to stabilize the optimization trajectory while still benefiting from smoothing to avoid sharp minima. This principled approach is well grounded from an optimization perspective and we show that a host of variations can be covered in a unified framework that we propose. We prove the convergence of this novel scheme and rigorously evaluate its empirical performance on ResNet, LSTM, and Transformer. We demonstrate that in a variety of experiments the scheme allows scaling to much larger batch sizes than before whilst reaching or surpassing SOTA accuracy.
- Is Local SGD Better than Minibatch SGD?AbstractVideoIn:ICML2020We study local SGD (also known as parallel SGD and federated averaging), a natural and frequently used stochastic distributed optimization method. Its theoretical foundations are currently lacking and we highlight how all existing error guarantees in the convex setting are dominated by a simple baseline, minibatch SGD. (1) For quadratic objectives we prove that local SGD strictly dominates minibatch SGD and that accelerated local SGD is minimax optimal for quadratics; (2) For general convex objectives we provide the first guarantee that at least sometimes improves over minibatch SGD; (3) We show that indeed local SGD does not dominate minibatch SGD by presenting a lower bound on the performance of local SGD that is worse than the minibatch SGD guarantee.
- Advances and Open Problems in Federated LearningAbstractFoundations and Trends® in Machine Learning14(1–2), 1–2102021Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
- SCAFFOLD: Stochastic Controlled Averaging for On-Device Federated LearningAbstractVideoIn:ICML2020Federated learning is a key scenario in modern large-scale machine learning. In that scenario, the training data remains distributed over a large number of clients, which may be phones, other mobile devices, or network sensors and a centralized model is learned without ever transmitting client data over the network. The standard optimization algorithm used in this scenario is Federated Averaging (FedAvg). However, when client data is heterogeneous, which is typical in applications, FedAvg does not admit a favorable convergence guarantee. This is because local updates on clients can drift apart, which also explains the slow convergence and hard-to-tune nature of FedAvg in practice. This paper presents a new Stochastic Controlled Averaging algorithm (SCAFFOLD) which uses control variates to reduce the drift between different clients. We prove that the algorithm requires significantly fewer rounds of communication and benefits from favorable convergence guarantees.
- Dynamic Model Pruning with FeedbackAbstractBibIn:ICLR2020Deep neural networks often have millions of parameters. This can hinder their deployment to low-end devices, not only due to high memory requirements but also because of increased latency at inference. We propose a novel model compression method that generates a sparse trained model without additional overhead: by allowing (i) dynamic allocation of the sparsity pattern and (ii) incorporating feedback signal to reactivate prematurely pruned weights we obtain a performant sparse model in one single training pass (retraining is not needed, but can further improve the performance). We evaluate the method on CIFAR-10 and ImageNet, and show that the obtained sparse models can reach the state-of-the-art performance of dense models and further that their performance surpasses all previously proposed pruning schemes (that come without feedback mechanisms).
- Decentralized Deep Learning with Arbitrary Communication CompressionAbstractBibIn:ICLR2020Decentralized training of deep learning models is a key element for enabling data privacy and on-device learning over networks, as well as for efficient scaling to large compute clusters. As current approaches suffer from limited bandwidth of the network, we propose the use of communication compression in the decentralized training context. We show that Choco-SGD&emdash;recently introduced and analyzed for strongly-convex objectives only&emdash;converges under arbitrary high compression ratio on general non-convex functions at the rate O(1/√(nT)) where T denotes the number of iterations and n the number of workers. The algorithm achieves linear speedup in the number of workers and supports higher compression than previous state-of-the art methods. We demonstrate the practical performance of the algorithm in two key scenarios: the training of deep learning models (i) over distributed user devices, connected by a social network and (ii) in a datacenter (outperforming all-reduce time-wise).
- Don't Use Large Mini-Batches, Use Local SGDAbstractBibIn:ICLR2020Mini-batch stochastic gradient methods (SGD) are state of the art for distributed training of deep neural networks. Drastic increases in the mini-batch sizes have lead to key efficiency and scalability gains in recent years. However, progress faces a major roadblock, as models trained with large batches often do not generalize well, i.e. they do not show good accuracy on new data. As a remedy, we propose a post-local SGD and show that it significantly improves the generalization performance compared to large-batch training on standard benchmarks while enjoying the same efficiency (time-to-accuracy) and scalability. We further provide an extensive study of the communication efficiency vs. performance trade-offs associated with a host of local SGD variants.
- Decentralized Stochastic Optimization and Gossip Algorithms with Compressed CommunicationAbstractVideoCodeBibIn:ICMLPMLR 97, 3478–34872019We consider decentralized stochastic optimization with the objective function (e.g. data samples for machine learning task) being distributed over n machines that can only communicate to their neighbors on a fixed communication graph. To reduce the communication bottleneck, the nodes compress (e.g. quantize or sparsify) their model updates. We cover both unbiased and biased compression operators with quality denoted by ω≤1 (ω=1 meaning no compression). We (i) propose a novel gossip-based stochastic gradient descent algorithm, CHOCO-SGD, that converges at rate O(1/(nT)+1/(Tδ2ω)2) for strongly convex objectives, where T denotes the number of iterations and δ the eigengap of the connectivity matrix. Despite compression quality and network connectivity affecting the higher order terms, the first term in the rate, O(1/(nT)), is the same as for the centralized baseline with exact communication. We (ii) present a novel gossip algorithm, CHOCO-GOSSIP, for the average consensus problem that converges in time O(1/(δ2ω)log(1/ε)) for accuracy ε>0. This is (up to our knowledge) the first gossip algorithm that supports arbitrary compressed messages for ω>0 and still exhibits linear convergence. We (iii) show in experiments that both of our algorithms do outperform the respective state-of-the-art baselines and CHOCO-SGD can reduce communication by at least two orders of magnitudes.
- Error Feedback Fixes SignSGD and other Gradient Compression SchemesAbstractCodeBibIn:ICMLPMLR 97, 3252–32612019Sign-based algorithms (e.g. signSGD) have been proposed as a biased gradient compression technique to alleviate the communication bottleneck in training large neural networks across multiple workers. We show simple convex counter-examples where signSGD does not converge to the optimum. Further, even when it does converge, signSGD may generalize poorly when compared with SGD. These issues arise because of the biased nature of the sign compression operator. We then show that using error-feedback, i.e. incorporating the error made by the compression operator into the next step, overcomes these issues. We prove that our algorithm EF-SGD achieves the same rate of convergence as SGD without any additional assumptions for arbitrary compression operators (including the sign operator), indicating that we get gradient compression for free. Our experiments thoroughly substantiate the theory showing the superiority of our algorithm.
- Local SGD Converges Fast and Communicates LittleAbstractPosterBibIn:ICLR2019
 Mini-batch stochastic gradient descent (SGD) is state of the art in large scale distributed training. The scheme can reach a linear speedup with respect to the number of workers, but this is rarely seen in practice as the scheme often suffers from large network delays and bandwidth limits. To overcome this communication bottleneck recent works propose to reduce the communication frequency. An algorithm of this type is local SGD that runs SGD independently in parallel on different workers and averages the sequences only once in a while. This scheme shows promising results in practice, but eluded thorough theoretical analysis.
Mini-batch stochastic gradient descent (SGD) is state of the art in large scale distributed training. The scheme can reach a linear speedup with respect to the number of workers, but this is rarely seen in practice as the scheme often suffers from large network delays and bandwidth limits. To overcome this communication bottleneck recent works propose to reduce the communication frequency. An algorithm of this type is local SGD that runs SGD independently in parallel on different workers and averages the sequences only once in a while. This scheme shows promising results in practice, but eluded thorough theoretical analysis.
We prove concise convergence rates for local SGD on convex problems and show that it converges at the same rate as mini-batch SGD in terms of number of evaluated gradients, that is, the scheme achieves linear speedup in the number of workers and mini-batch size. The number of communication rounds can be reduced up to a factor of T^{1/2}---where T denotes the number of total steps---compared to mini-batch SGD. This also holds for asynchronous implementations.
Local SGD can also be used for large scale training of deep learning models. The results shown here aim serving as a guideline to further explore the theoretical and practical aspects of local SGD in these applications. - Efficient Greedy Coordinate Descent for Composite ProblemsAbstractBibIn:AISTATSPMLR 89, 2887–28962019Coordinate descent with random coordinate selection is the current state of the art for many large scale optimization problems. However, greedy selection of the steepest coordinate on smooth problems can yield convergence rates independent of the dimension n, and requiring upto n times fewer iterations.
In this paper, we consider greedy updates that are based on subgradients for a class of non-smooth composite problems, which includes L1-regularized problems, SVMs and related applications. For these problems we provide (i) the first linear rates of convergence independent of n, and show that our greedy update rule provides speedups similar to those obtained in the smooth case. This was previously conjectured to be true for a stronger greedy coordinate selection strategy.
Furthermore, we show that (ii) our new selection rule can be mapped to instances of maximum inner product search, allowing to leverage standard nearest neighbor algorithms to speed up the implementation. We demonstrate the validity of the approach through extensive numerical experiments. - Sparsified SGD with MemoryAbstractPosterCodeBibIn:NeurIPS31, 4452–44632018
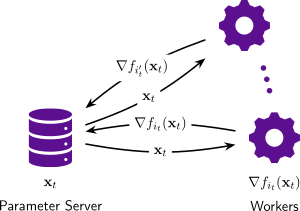 Huge scale machine learning problems are nowadays tackled by distributed optimization algorithms, i.e. algorithms that leverage the compute power of many devices for training. The communication overhead is a key bottleneck that hinders perfect scalability. Various recent works proposed to use quantization or sparsification techniques to reduce the amount of data that needs to be communicated, for instance by only sending the most significant entries of the stochastic gradient (top-k sparsification). Whilst such schemes showed very promising performance in practice, they have eluded theoretical analysis so far.
Huge scale machine learning problems are nowadays tackled by distributed optimization algorithms, i.e. algorithms that leverage the compute power of many devices for training. The communication overhead is a key bottleneck that hinders perfect scalability. Various recent works proposed to use quantization or sparsification techniques to reduce the amount of data that needs to be communicated, for instance by only sending the most significant entries of the stochastic gradient (top-k sparsification). Whilst such schemes showed very promising performance in practice, they have eluded theoretical analysis so far.
In this work we analyze Stochastic Gradient Descent (SGD) with k-sparsification or compression (for instance top-k or random-k) and show that this scheme converges at the same rate as vanilla SGD when equipped with error compensation (keeping track of accumulated errors in memory). That is, communication can be reduced by a factor of the dimension of the problem (sometimes even more) whilst still converging at the same rate. We present numerical experiments to illustrate the theoretical findings and the better scalability for distributed applications. - Global linear convergence of Newton's method without strong-convexity or Lipschitz gradientsBibIn:NeurIPS 2019 Workshop: Beyond First Order Methods in ML2018
- Accelerated Stochastic Matrix Inversion: General Theory and Speeding up BFGS Rules for Faster Second-Order OptimizationAbstractPosterBibIn:NeurIPS31, 1626–16362018We present the first accelerated randomized algorithm for solving linear systems in Euclidean spaces. One essential problem of this type is the matrix inversion problem. In particular, our algorithm can be specialized to invert positive definite matrices in such a way that all iterates (approximate solutions) generated by the algorithm are positive definite matrices themselves. This opens the way for many applications in the field of optimization and machine learning. As an application of our general theory, we develop the first accelerated (deterministic and stochastic) quasi-Newton updates. Our updates lead to provably more aggressive approximations of the inverse Hessian, and lead to speed-ups over classical non-accelerated rules in numerical experiments. Experiments with empirical risk minimization show that our rules can accelerate training of machine learning models.
- On Matching Pursuit and Coordinate DescentBibIn:ICMLPMLR 80, 3198–32072018
- Adaptive balancing of gradient and update computation times using global geometry and approximate subproblemsSlidesBibIn:AISTATSPMLR 84, 1204–12132018
- Safe Adaptive Importance SamplingVideoSlidesPosterBibSpotlight talk, In:NIPS30, 4381–43912017
- On the existence of ordinary trianglesBibComputational Geometry66, 28–312017
- Approximate Steepest Coordinate DescentPosterBibIn:ICMLPMLR 70, 3251–32592017
- Efficiency of accelerated coordinate descent method on structured optimization problemsBibSIAM Journal on Optimization27:1, 110–1232017
- Variable Metric Random PursuitBibMathematical Programming156(1), 549–5792016
- On two continuum armed bandit problems in high dimensionsBibTheory of Computing Systems58:1, 191–2222016
- On low complexity Acceleration Techniques for Randomized OptimizationSupplBibIn:PPSN XIIISpringer, 130–1402014
- Optimization of Convex Functions with Random PursuitBibSIAM Journal on Optimization23:2, 1284–13092013
- On spectral invariance of Randomized Hessian and Covariance Matrix Adaptation schemesPosterBibIn:PPSN XIISpringer, 448–4572012
- On Two Problems Regarding the Hamiltonian Cycle GameBibThe Electronic Journal of Combinatorics16(1)2009
Preprints / Various:
- Characterizing & Finding Good Data Orderings for Fast Convergence of Sequential Gradient MethodsAbstractTechnical Report2022While SGD, which samples from the data with replacement is widely studied in theory, a variant called Random Reshuffling (RR) is more common in practice. RR iterates through random permutations of the dataset and has been shown to converge faster than SGD. When the order is chosen deterministically, a variant called incremental gradient descent (IG), the existing convergence bounds show improvement over SGD but are worse than RR. However, these bounds do not differentiate between a good and a bad ordering and hold for the worst choice of order. Meanwhile, in some cases, choosing the right order when using IG can lead to convergence faster than RR. In this work, we quantify the effect of order on convergence speed, obtaining convergence bounds based on the chosen sequence of permutations while also recovering previous results for RR. In addition, we show benefits of using structured shuffling when various levels of abstractions (e.g. tasks, classes, augmentations, etc.) exists in the dataset in theory and in practice. Finally, relying on our measure, we develop a greedy algorithm for choosing good orders during training, achieving superior performance (by more than 14 percent in accuracy) over RR.
- ProxSkip: Yes! Local Gradient Steps Provably Lead to Communication Acceleration! Finally!AbstractTechnical Report2022We introduce ProxSkip -- a surprisingly simple and provably efficient method for minimizing the sum of a smooth (f) and an expensive nonsmooth proximable (ψ) function. The canonical approach to solving such problems is via the proximal gradient descent (ProxGD) algorithm, which is based on the evaluation of the gradient of f and the prox operator of ψ in each iteration. In this work we are specifically interested in the regime in which the evaluation of prox is costly relative to the evaluation of the gradient, which is the case in many applications. ProxSkip allows for the expensive prox operator to be skipped in most iterations. Our main motivation comes from federated learning, where evaluation of the gradient operator corresponds to taking a local GD step independently on all devices, and evaluation of prox corresponds to (expensive) communication in the form of gradient averaging. In this context, ProxSkip offers an effective acceleration of communication complexity. Unlike other local gradient-type methods, such as FedAvg, SCAFFOLD, S-Local-GD and FedLin, whose theoretical communication complexity is worse than, or at best matching, that of vanilla GD in the heterogeneous data regime, we obtain a provable and large improvement without any heterogeneity-bounding assumptions.
- Linear Speedup in Personalized Collaborative LearningAbstractTechnical Report2021Personalization in federated learning can improve the accuracy of a model for a user by trading off the model's bias (introduced by using data from other users who are potentially different) against its variance (due to the limited amount of data on any single user). In order to develop training algorithms that optimally balance this trade-off, it is necessary to extend our theoretical foundations. In this work, we formalize the personalized collaborative learning problem as stochastic optimization of a user's objective f0(x) while given access to N related but different objectives of other users {f1(x),…,fN(x)}. We give convergence guarantees for two algorithms in this setting -- a popular personalization method known as weighted gradient averaging, and a novel bias correction method -- and explore conditions under which we can optimally trade-off their bias for a reduction in variance and achieve linear speedup w.r.t. the number of users N. Further, we also empirically study their performance confirming our theoretical insights.
- ProgFed: Effective, Communication, and Computation Efficient Federated Learning by Progressive TrainingAbstractTechnical Report2021Federated learning is a powerful distributed learning scheme that allows numerous edge devices to collaboratively train a model without sharing their data. However, training is resource-intensive for edge devices, and limited network bandwidth is often the main bottleneck. Prior work often overcomes the constraints by condensing the models or messages into compact formats, e.g., by gradient compression or distillation. In contrast, we propose ProgFed, the first progressive training framework for efficient and effective federated learning. It inherently reduces computation and two-way communication costs while maintaining the strong performance of the final models. We theoretically prove that ProgFed converges at the same asymptotic rate as standard training on full models. Extensive results on a broad range of architectures, including CNNs (VGG, ResNet, ConvNets) and U-nets, and diverse tasks from simple classification to medical image segmentation show that our highly effective training approach saves up to 20% computation and up to 63% communication costs for converged models. As our approach is also complimentary to prior work on compression, we can achieve a wide range of trade-offs, showing reduced communication of up to 50× at only 0.1% loss in utility.
- Escaping Local Minima With Stochastic NoiseAbstractIn:NeurIPS 2021 Workshop: Optimization for Machine Learning2021Non-convex optimization problems are ubiquitous in machine learning, especially in Deep Learning. While such complex problems can often be successfully optimized in practice by using stochastic gradient descent (SGD), theoretical analysis cannot adequately explain this success. In particular, the standard analyses don’t show global convergence of SGD on non-convex functions, and instead show convergence to stationary points (which can also be local minima or saddle points). In this work, we identify a broad class of nonconvex functions for which we can show that perturbed SGD (gradient descent perturbed by stochastic noise—covering SGD as a special case) converges to a global minimum, in contrast to gradient descent without noise that can get stuck in local minima. In particular, for non-convex functions that are relative close to a convex-like (strongly convex or PŁ) function we prove that SGD converges linearly to a global optimum.
- On Second-order Optimization Methods for Federated LearningAbstractIn:ICML 2021 Workshop: Beyond first-order methods in ML systems2021We consider federated learning (FL), where the training data is distributed across a large number of clients. The standard optimization method in this setting is Federated Averaging (FedAvg), which performs multiple local first-order optimization steps between communication rounds. In this work, we evaluate the performance of several second-order distributed methods with local steps in the FL setting which promise to have favorable convergence properties. We (i) show that FedAvg performs surprisingly well against its second-order competitors when evaluated under fair metrics (equal amount of local computations)-in contrast to the results of previous work. Based on our numerical study, we propose (ii) a novel variant that uses second-order local information for updates and a global line search to counteract the resulting local specificity.
- Bi-directional Adaptive Communication for Heterogenous Distributed LearningAbstractIn:ICML 2021 Workshop: Federated Learning for User Privacy and Data Confidentiality2021Communication constraints are a key bottleneck in distributed optimization, in particularly bandwidth and latency can be limiting factors when devices are connected over commodity networks, such as in Federated Learning. State-of-the-art techniques tackle these challenges by advanced compression techniques or delaying communication rounds according to predefined schedules. We present a new scheme that adaptively skips communication (broadcast and client uploads) by detecting slow-varying updates. The scheme automatically adjusts the communication frequency independently for each worker and the server. By utilizing an error-feedback mechanism – borrowed from the compression literature – we prove that the convergence rate is the same as for batch gradient descent in the convex and nonconvex smooth cases. We show reduction of the total number of communication rounds between server and clients needed to achieve a targeted accuracy, even in the case when the data distribution is highly non-IID.
- A Field Guide to Federated OptimizationAbstractTechnical Report2021Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
- Decentralized Local Stochastic Extra-Gradient for Variational InequalitiesAbstractTechnical Report2021We consider decentralized stochastic variational inequalities where the problem data is distributed across many participating devices (heterogeneous, or non-IID data setting). We propose a novel method - based on stochastic extra-gradient - where participating devices can communicate over arbitrary, possibly time-varying network topologies. This covers both the fully decentralized optimization setting and the centralized topologies commonly used in Federated Learning. Our method further supports multiple local updates on the workers for reducing the communication frequency between workers. We theoretically analyze the proposed scheme in the strongly monotone, monotone and non-monotone setting. As a special case, our method and analysis apply in particular to decentralized stochastic min-max problems which are being studied with increased interest in Deep Learning. For example, the training objective of Generative Adversarial Networks (GANs) are typically saddle point problems and the decentralized training of GANs has been reported to be extremely challenging. While SOTA techniques rely on either repeated gossip rounds or proximal updates, we alleviate both of these requirements. Experimental results for decentralized GAN demonstrate the effectiveness of our proposed algorithm.
- On Communication Compression for Distributed Optimization on Heterogeneous DataAbstractTechnical Report2020Lossy gradient compression, with either unbiased or biased compressors, has become a key tool to avoid the communication bottleneck in centrally coordinated distributed training of machine learning models. We analyze the performance of two standard and general types of methods: (i) distributed quantized SGD (D-QSGD) with arbitrary unbiased quantizers and (ii) distributed SGD with error-feedback and biased compressors (D-EF-SGD) in the heterogeneous (non-iid) data setting. Our results indicate that D-EF-SGD is much less affected than D-QSGD by non-iid data, but both methods can suffer a slowdown if data-skewness is high. We propose two alternatives that are not (or much less) affected by heterogenous data distributions: a new method that is only applicable to strongly convex problems, and we point out a more general approach that is applicable to linear compressors.
- On the Convergence of SGD with Biased GradientsAbstractIn:ICML 2020 Workshop: Beyond First Order Methods in ML Systems2020The classic stochastic gradient (SGD) algorithm crucially depends on the availability of unbiased stochastic gradient oracles. However, in certain applications only biased gradient updates are available or preferred over unbiased ones for performance reasons. For instance, in the domain of distributed learning, biased gradient compression techniques such as top-$k$ compression have been proposed as a tool to alleviate the communication bottleneck and in derivative-free optimization, only biased gradient estimators can be queried.
We present a general framework to analyze SGD with biased gradient oracles and derive convergence rates for smooth (non-convex) functions and give improved rates under the Polyak-Lojasiewicz condition. Our rates show how biased estimators impact the attainable convergence guarantees. We discuss a few guiding examples that show the broad applicability of our analysis. - Unified Optimal Analysis of the (Stochastic) Gradient MethodAbstractBibTechnical Report2019In this note we give a simple proof for the convergence of stochastic gradient (SGD) methods on μ-strongly convex functions under a (milder than standard) L-smoothness assumption. We show that SGD converges after T iterations as O(L∥x0−x*∥² exp[−μT/4L]+σ²/μT) where σ² measures the variance. For deterministic gradient descent (GD) and SGD in the interpolation setting we have σ²=0 and we recover the exponential convergence rate. The bound matches with the best known iteration complexity of GD and SGD, up to constants.
- Stochastic Distributed Learning with Gradient Quantization and Variance ReductionAbstractBibTechnical Report2019We consider distributed optimization where the objective function is spread among different devices, each sending incremental model updates to a central server. To alleviate the communication bottleneck, recent work proposed various schemes to compress (e.g. quantize or sparsify) the gradients, thereby introducing additional variance ω≥1 that might slow down convergence. For strongly convex functions with condition number κ distributed among n machines, we (i) give a scheme that converges in O((κ+κωn+ω) log(1/ϵ)) steps to a neighborhood of the optimal solution. For objective functions with a finite-sum structure, each worker having less than m components, we (ii) present novel variance reduced schemes that converge in O((κ+κωn+ω+m)log(1/ϵ)) steps to arbitrary accuracy ϵ>0. These are the first methods that achieve linear convergence for arbitrary quantized updates. We also (iii) give analysis for the weakly convex and non-convex cases and (iv) verify in experiments that our novel variance reduced schemes are more efficient than the baselines.
- k-SVRG: Variance Reduction for Large Scale OptimizationBibTechnical Report2018
- Stochastic continuum armed bandit problem of few linear parameters in high dimensionsBibTechnical Report2013
- Random Pursuit in Hilbert SpaceBibTechnical ReportCGL-TR-882013
- Matrix-valued Iterative Random ProjectionsBibTechnical ReportCGL-TR-872013
Theses
- Convex Optimization with Random PursuitBibPhD thesis in Theoretical Computer ScienceETH Zurich2014
- Graph sparsification and applicationsBibMaster thesis in MathematicsETH Zurich2010
- On two problems regarding the Hamilton Cycle GamePaperBibBachelor thesis in MathematicsETH Zurich2008
Talks / Posters / Workshops
- 13/14 December202113th Workshop on Optimization for Machine Learning (OPT)(workshop organizer)VirtualOnlineWorkshop
- Algorithms for Efficient Federated and Decentralized Learning(keynote, invited)24 July2021International Workshop on Federated Learning for User Privacy and Data ConfidentialityVirtualOnline
- Asynchronous Methods in Distributed Optimization and Insights from the Error-Feedback Framework(invited session)Slides20–23 July2021SIAM Conference on Optimization (OP21)Spokane, WashingtonUSA
- Escaping local minima for a class of smooth non-convex problems(invited)14 July2021Optimization without BordersHybrid, SochiRussia
- Taming GANs with Lookahead-Minmax (talk by Matteo Pagliardini)Video3 May–7 May2021International Conference on Learning Representations (ICLR)VirtualOnline
- 11 December202012th Workshop on Optimization for Machine Learning (OPT)(workshop organizer)Virtual, formerly VancouverOnlineWorkshop
- Towards Decentralized Machine Learning with SGD12 November2020SeminarETH ZurichSwitzerland
- A Unified Theory of Decentralized SGD with Changing Topology and Local Updates (talk by Anastasia Koloskova)VideoExtrapolation for Large-batch Training in Deep Learning (talk by Tao Lin)VideoIs Local SGD Better than Minibatch SGD? (talk by Blake Woodworth)VideoSCAFFOLD: Stochastic Controlled Averaging for Federated Learning (talk by Praneeth Karimireddy)Video12–18 July202037th International Conference on Machine Learning (ICML)Virtual conference, formerly ViennaOnline
- Decentralized Deep Learning with Arbitrary Communication Compression (talk by Anastasia Koloskova)VideoDon't Use Large Mini-batches, Use Local SGD (talk by Tao Lin)VideoDynamic Model Pruning with Feedback (talk by Tao Lin)Video26 April–1st May2020International Conference on Learning Representations (ICLR)Virtual Conference, formerly Addis AbabaOnline
- 27 February2020research visit Suvrit Sra, MITCambridge MAUSA
- A Unifying Framework for Communication Efficient Decentralized Machine Learning20 February2020MLO Group SeminarLausanneSwitzerland
- Advances in ML: Theory meets Practice (workshop organizer)Workshop25–29 January2020Applied Machine Learning DaysEPFL LausanneSwitzerland
- 14 December201911th Workshop on Optimization for Machine Learning (OPT)(workshop organizer)VancouverCanadaWorkshop
- 8–14 December2019Thirty-third Conference on Neural Information Processing Systems (NeurIPS)VancouverCanada
- 23–26 November2019KAUST-Tsinghua Industry Workshop on Advances in Artificial IntelligenceThuwalKSA
- 17–29 November2019research visit Peter Richtárik, KAUSTThuwalKSA
- 22–30 October2019research visit Yurii Nesterov, UCLouvainLouvain-la-NeuveBelgium
- Tutorial On Theory of Federated Learning15 October2019MLO SeminarLausanneSwitzerland
- Communication Efficient Variants of SGD for Distributed Training(invited session)5–8 August20196th International Conference on Continuous Optimization (ICCOPT)BerlinGermany
- On Lottery Tickets in DL5 July2019EPFL, ML-Theory SeminarLausanneSwitzerland
- Variance Reduced Methods in Derivative Free Optimization(invited session)24–26 June201930th European Conference on Operational Research (EURO)DublinIreland
- Decentralized Stochastic Optimization and Gossip Algorithms with Compressed CommunicationError Feedback Fixes SignSGD and other Gradient Compression Schemes(talk by Praneeth)9–15 June201936th International Conference on Machine Learning (ICML)Long BeachUSA
- Gradient Compression with Error Feedback for Distributed Optimization(invited)4 June2019OwkinParisFrance
- Gradient Compression with Error Feedback for Distributed Optimization(invited)3 June2019Séminaire Parisien d'OptimisationParisFrance
- Tutorial On Robust Optimization28 May2019MLO SeminarLausanneSwitzerland
- Local SGD Converges Fast and Communicates LittlePoster6–9 May2019International Conference on Learning Representations (ICLR)New OrleansUSA
- Communication Efficient SGD for Distributed Optimization(invited)20–22 March2019Operator Splitting Methods in Data Analysis WorkshopFlatiron Institute, New YorkUSA
- Error Feedback for Communication Efficient SGD(Machine Learning Seminar UChicago and TTIC, invited)11–15 March2019research visit Nati Srebo, Toyota Technological Institute at Chicago (TTIC)ChicagoUSA
- Error Feedback for Communication Efficient SGD(invited)14 February2019MPITübingenGermany
- Advances in ML: Theory meets Practice(workshop organizer)Workshop26–29 January2019Applied Machine Learning DaysEPFL LausanneSwitzerland
- Sparsified SGD with MemoryPosterAccelerated Stochastic Matrix Inversion: General Theory and Speeding up BFGS Rules for Faster Second-Order OptimizationPoster2–8 December2018Thirty-second Annual Conference on Neural Information Processing Systems (NeurIPS)MontréalCanada
- Communication Efficient Variants of SGD for Distributed Computing23 November2018Machine Learning meeting, EPFLLausanneSwitzerland
- Communication Efficient Variants of SGD for Distributed Computing(CS Graduate Seminar, invited)k-SVRG: Variance Reduction for Large Scale Optimization(All Hands Meetings on Big Data Optimization)23 October–14 November2018research visit Peter Richtárik, KAUSTThuwalKSA
- Tutorial On Convex and Non-Convex Optimization26 September2018MLO SeminarLausanneSwitzerland
- Communication Efficient Variants of SGD for Distributed Computing(CORE–INMA Seminar, invited)2–14 September2018research visit François Glineur, Yurii Nesterov, UCLouvainLouvain-la-NeuveBelgium
- Communication Efficient SGD through Quantization with Memory30 August2018MittagsseminarETH ZürichSwitzerland
- On Matching Pursuit and Coordinate Descent(talk by Francesco)10–15 July201835th International Conference on Machine Learning (ICML)StockholmSweden
- Approximate Composite Minimization: Convergence Rates and Examples(invited session)2–6 July201823rd International Symposium on Mathematical Programming (ISMP)BordeauxFrance
- Tutorial On Random Pursuit Methods13 June2018MLO SeminarLausanneSwitzerland
- Adaptive balancing of gradient and update computation times(talk by Praneeth)9–11 April2018The 21st International Conference on Artificial Intelligence and Statistics (AISTATS)Playa Blanca, LanzaroteSpain
- 19–20 February2018Swiss Joint Research Center Workshop 2018EPFL LausanneSwitzerland
- Advances in ML: Theory meets Practice(workshop organizer)Workshop27–30 January2018Applied Machine Learning DaysEPFL LausanneSwitzerland
- Adaptive importance sampling for convex optimization(invited)15–18 January2018Optimization for Learning WorkshopPontificia Universidad Católica de Chile, SantiagoChile
- Adaptive importance sampling for convex optimization(invited)2–13 January2018research visit Hemant Tyagi, Alan Touring InstituteLondonUK
- Safe Adaptive Importance Sampling4–9 December2017Thirty-first Annual Conference on Neural Information Processing Systems (NIPS)Long BeachUSAPoster
- 27 November – 1 December2017Optimization, Statistics and Uncertainty Simons Institute for the Theory of Computing, BerkelyUSA
- Approximate Steepest Coordinate Descent3–21 October2017research visit Peter Richtárik, KAUSTThuwalKSA
- Tutorial On Coordinate Descent30 August2017MLO SeminarLausanneSwitzerland
- Approximate Steepest Coordinate Descent6–11 August201734th International Conference on Machine Learning (ICML)SidneyAustraliaPoster
- 14–16 June2017The Summer Research Institute 2017EPFL LausanneSwitzerland
- 12–14 June2017Google Machine Learning SummitGoogle ZürichSwitzerland
- Efficiency of Coordinate Descent on Structured Problems(invited session)22–25 May2017SIAM Conference on Optimization (OP17)VancouverCanada
- 2–3 February2017Swiss Joint Research Center Workshop 2017Microsoft CambridgeUK
- 30–31 January2017Applied Machine Learning DaysEPFL LausanneSwitzerland
- 5–10 December2016Thirtieth Annual Conference on Neural Information Processing Systems (NIPS)BarcelonaSpain
- Randomized Algorithms for Convex Optimization18 October2016Operations Research SeminarCORE, Louvain-la-NeuveBelgium
- Efficiency of Random Search on Structured Problems(invited session)6–11 August20165th International Conference on Continuous Optimization (ICCOPT)TokyoJapan
- 6–10 June201614th Gremo Workshop on Open ProblemsSt. NiklausenSwitzerland
- Adaptive Quasi-Newton Methods(invited)6 June20169th Combinatorial Algorithms DayETH ZürichSwitzerland
- 11 April–15 April2016research visit Peter Richtárik, University of EdinburghEdinburghUK
- 7–12 February2016Optimization Without Borders—dedicated to the 60th birthday of Yuri NesterovLes HouchesFrance
- Efficient Methods for a Class of Truss Topology Design Problems28–29 January201630th annual conference of the Belgian Operational Research Society (ORBEL)Louvain-la-NeuveBelgium
- 23 November2015IAP DYSCO Study Day: Dynamical systems, control and optimizationLeuvenBelgium
- 26 October – 20 November2015SOCN Grad Course: Randomized algorithms for big data optimizationLouvain-la-NeuveBelgium
- Accelerated Random Search8–10 July201513th EUROPT Workshop on Advances in Continuous OptimizationEdinburghUK
- 1–5 June201513th Gremo Workshop on Open ProblemsFeldisSwitzerland
- Solving generalized Laplacian linear systems(invited)1 June20158th Combinatorial Algorithms DayETH ZürichSwitzerland
- 6–8 May2015Optimization and Big Data 2015, Workshop, Trek and ColloquiumEdinburghUK
- 12 November2014IAP DYSCO Study Day: Dynamical systems, control and optimizationGentBelgium
- Optimization of convex function with Random Pursuit(invited)4 November2014Simons FoundationNew YorkUSA
- 30 October–6 November2016research visit Christian Müller, Simons FoundationNew YorkUSA
- On Low Complexity Acceleration Techniques for Randomized Optimization13–17 September201413th International Conference on Parallel Problem Solving From Nature (PPSN)LjubljanaSlovenia
- 30 June – 4 July201412th Gremo Workshop on Open ProblemsVal SinestraSwitzerland
- 30 June20147th Combinatorial Algorithms DayETH ZürichSwitzerland
- Probabilistic Estimate Sequences4–5 April2014Workshop on Theory of Randomized Search Heuristics (ThRaSH) 2014JenaGermany
- Probabilistic Estimate Sequences(invited)25 March2014TAO reserach seminarINRIA Saclay, Île-de-FranceFrance
- Natural Gradient in Evolution Strategies17 October2013MittagsseminarETH ZürichSwitzerland
- Optimization and Learning with Random Pursuit30 September – 2 Oktober2013CG Learning Review MeetingAthensGreece
- 30 June – 5 July2013Dagstuhl Seminar "Theory of Evolutionary Algorithms"WadernGermany
- 24–28 June201311th Gremo Workshop on Open ProblemsAlp SellamattSwitzerland
- 24 June20136th Combinatorial Algorithms DayETH ZürichSwitzerland
- Stochastic Bandits30 May2013MittagsseminarETH ZürichSwitzerland
- 6 April – 8 May2013Research visit with Christian Müller and Jonathan GoodmanCourant Institute of Mathematical Sciences, New York UniversityUSA
- Variable Metric Random Pursuit13–14 December2012CG Learning Review MeetingBerlinGermany
- Variable Metric Random Pursuit4 December2012MittagsseminarETH ZürichSwitzerland
- On spectral invariance of Randomized Hessian and Covariance Matrix Adaptation schemesPoster1–5 September201212th International Conference on Parallel Problem Solving From Nature (PPSN)TaorminaItaly
- Convergence of Local Search19–24 August201221st International Symposium on Mathematical Programming (ISMP)TU BerlinGermany
- 20–22 June201212th International Workshop on High Performance Optimization (HPOPT): Algorithmic convexity and applicationsDelft University of TechnologyThe Netherlands
- 4–8 June201210th Gremo Workshop on Open ProblemsBergünSwitzerland
- 4 June20125th Combinatorial Algorithms DayETH ZürichSwitzerland
- Convergence of Local Search2–3 May2012Workshop on Theory of Randomized Search Heuristics (ThRaSH) 2012Lille/Villeneuve d'AscqFrance
- The Heavy Ball Method3 April2012MittagsseminarETH ZürichSwitzerland
- Advertising Randomized derivative-free optimization11–14 March2012The First ETH-Japan Workshop on Science and ComputingEngelbergSwitzerland
- 7–9 March2012The First ETH-Japan Symposium for the Promotion of Academic ExchangesETH ZürichSwitzerland
- Gradient-free optimization with Random Pursuit15 December2011CG Learning Review MeetingZürichSwitzerland
- Dimension reduction with the Johnson-Lindenstrauss Lemma29 September2011MittagsseminarETH ZürichSwitzerland
- 30 August – 2 September2011International Conference on Operations ResearchZürichSwitzerland
- Randomized Derivative-Free Optimization, a survery of different methodsPoster8–11 August2011MADALGO & CTIC Summer School on High-dimensional Geometric ComputingAarhus UniversityDanmark
- Random derivative-free optimization of convex functions using a line search oracle8–9 July2011Workshop on Theory of Randomized Search Heuristics (ThRaSH) 2011CopenhagenDanmark
- 4–8 July201138th International Colloquium on Automata, Languages and Programming (ICALP)ZürichSwitzerland
- 9–11 June2011CG Learning Kick-off WorkshopParisFrance
- 28–30 March201127th European Workshop on Computational Geometry (EuroCG)MorschachSwitzerland
- 7–10 February20119th Gremo Workshop on Open ProblemsWergensteinSwitzerland
- Principles of self-adaptation in randomized optimization16 December2010MittagsseminarETH ZürichSwitzerland
- Graph sparsification with applications11 March2010Institute for Operations Research (IFOR)ETH ZürichSwitzerland
Student Projects
- Pedram KhorsandiMomentum Methods in DLSummer Intern (Virtual)2021
- Yehao LiuUncertainity Estimation in DLMaster Project2021Paper
- Yue Liu (now graduate student at U Toronto)Variance reduction on decentralized training over heterogeneous dataMaster Thesis2021
- Giovanni IgowaCompression and Training for DLBachelor Project2021
- Ilyas Fatkhullin (now PhD student at ETH Zurich)Robust Acceleration with Error FeedbackSummer Intern (Virtual)2020
- Oguz Kaan YükselSemantic Perturbations with Normalizing Flows for Improved GeneralizationMaster Project2021Paper
- Nicolas Brandt-Dit-GrieurinAdaptive Optimization Methods in DLMaster Project2020
- Sophie MauranModel Parallel Training of DNNMaster Project2020
- Pierre VuillecardPreconditioned SGD For DLMaster Project2020
- Thomas de Boissonneaux de ChevignyOn DeAI SimulatorsBachelor Project2020
- Manjot SinghThe Interplay between Noise and CurvatureOptional Master Project2020
- Damian Dudzicz (now exchange student at ETH)Push-Sum Algorithms for Decentralized OptimizationMaster Project2020
- Harshvardhan Harshvardhan (now graduate student at UC San Diego)Convergence-Diagnostic based Adaptive Batch Sizes for SGDOptional Project2020
- Pavlo KaralupovImportance Sampling to Accelerate DL TrainingMaster Project2020
- Raphael BonattiOn Solving Combinatorial Games with Neural NetworksBachelor Project2020
- Sebastian BischoffImportance Sampling to Accelerate DL TrainingMaster Project2020
- Sadra BoreiriDecentralized Local SGDMaster Project2019Paper
- Damian Dudzicz (now exchange student at ETH)Decentralized Asynchronous SGDMaster Project2019
- Oriol Barbany Mayor (now at Logitec)Affine-Invariant Robust TrainingMaster Project2019
- Rayan ElalamyConvergence Anlysis for Hogwild! Under Less Restrictive AssumptionsMaster Project2019
- Lionel ConstantinStochastic Extragradient for GAN TrainingMaster Project2019
- Harshvardhan HarshvardhanBetter bounds for Optimal Batch Size in SGDMaster Project2019
- Srijan Bansal (now at IIT Kharagpur)Adaptive Stepsize Strategies for SGDSummer Internship2019
- Guillaume van Dessel (now PhD student at UCLouvain)Stochastic gradient based methods for large-scale optimization: review, unification and new approachesMaster Thesis2019
- Ahmad Ajalloeian (now PhD student at UNIL)Stochastic Zeroth-Order Optimisation Algorithms with Variance ReductionMaster Thesis2019
- Claire Capelo (now exchange student at Stanford)Adaptive schemes for communication compression: Trajectory Normalized Gradients for Distributed OptimizationMaster Project2019
- Aakash Sunil Lahoti Special Cases of Local SGDMaster Project2019
- Cem Musluoglu (now PhD student at KU Leuven)Quantization and Compression for Distributed OptimizationMaster Project2018
- Quentin Rebjock (now PhD student at EPFL)Error Feedback For SignSGDMaster Project2018Paper
- Jimi Vaubien (now at Visum Technologies)Derivative-Free Empirical Risk MinimizationBachelor Project2018
- Polina Kirichenko (now PhD student at NYU)Zero-order training for DLSummer Internship2018
- Nikhil Krishna (now at Detect Technologies)Adaptive Sampling with LSHSummer Internship2018
- Alberto Chiappa (now at Schindler Group)Real-time recognition of industry-specific context from mobile phone sensor dataMaster Thesis (industry project with Schindler)2018
- Jean-Baptiste Cordonnier (now PhD student at EPFL)Distributed Machine Learning with Sparsified Stochastic Gradient DescentMaster Thesis2018Paper
- Arthur Deschamps (now research intern at National University of Singapore)Asynchronous Methods in Machine LearningBachelor Project2018
- Chia-An Yu (now at Bloomberg)Compression for Stochastic Gradient DescentMaster Project2018
- Frederik Künstner (now PhD student at UBC)Fully Quantized Distributed Gradient DescentMaster Project2017
- Fabian Latorre Gomez (now PhD Student at EPFL)Importance Sampling for MLEDIC Project2017
- Pooja Kulkarni (now PhD student at UIUC)Steepest Descent and Adaptive SamplingSummer Internship2017
- Anastasia Koloskova (now PhD student at EPFL)Steepest CD and LSHSummer Internship2017Paper
- William Borgeaud dit AvocatAdaptive Sampling in Stochastic Coordinate DescentMaster Project2017
- Joel Castellon (now at Amazon)Complexity analysis for AdaRBFGS: a primitive for methods between first and second orderSemester Project2017
- Alberto Chiappa (now at Schindler Group)Asynchronous updates for stochastic gradient descentMaster Project2017
- Marina Mannari (now at Cartier)Faster Coordinate Descent for Machine Learning through Limited Precision OperationsMaster Thesis2017
- Anant Raj (now PhD student at MPI)Steepest Coordinate DescentInternship2017Paper
Teaching
Lectures
- Optimization for Machine LearningSummer 24
- Games in Machine LearningWinter 23
- Optimization for Machine LearningSummer 23
- Optimization for Machine LearningSummer 22
Seminars
- Topics in Optimization for Machine LearningWinter 24
- Optimization Methods for Large-Scale Machine LearningSummer 23
- Topics in Optimization for Machine LearningWinter 22
- Topics in Optimization for Machine LearningWinter 21
Teaching Assistance
- Game TheorySpring 2016
- Algorithms LabFall 2013
- Informaticsfor mathematics and physics (in C++) (head assistant)Fall 2013
- Algorithms LabFall 2012
- Informaticsfor mathematics and physics (in C++)Fall 2012
- Approximation Algorithms and Semidefinite Programming(head assistant)Spring 2012
- Algorithms LabFall 2011
- Informaticsfor mathematics and physics (in C++)Fall 2010
- Analysis Ifor mechanical engineeringFall 2009
- Analysis IIfor mechanical engineeringSpring 2009
- Analysis Ifor mechanical engineeringFall 2008
- Analysis IIfor mechanical engineeringSpring 2008
- Complex AnalysisFall 2007